After achieving a significant improvement in the accuracy of text extracted from the FT Archives (scans of every page of every issue since 1888) using just the default settings of Tesseract (see previous blog post), we still had whole decades of FT issues where the OCR had failed to extract any meaningful text from the scanned images of the pages. Since we (humans) could read the text in most of those images ok, it was obviously possible to extract meaning from them. We persevered with Tesseract, in particular its training feature.
Training Tesseract
Tesseract is powered by a neural network which can be fed new examples of what various alphanumeric characters look like in a variety of contexts. Each item of training data is one instance of one character, including the correct value of the character, its location in the image of the article, and the cropped image of that one character extracted from the page image.
But how do we get such precise coordinates and images for each and every character of every article in every page of every issue? From Tesseract. When Tesseract scans a document, it will typically dump the text it finds into a text file in one whole piece with limited effort having been made to maintain the structure of the document, but Tesseract can also be told to instead to dump out a text file with the coordinates of each character image it identified.
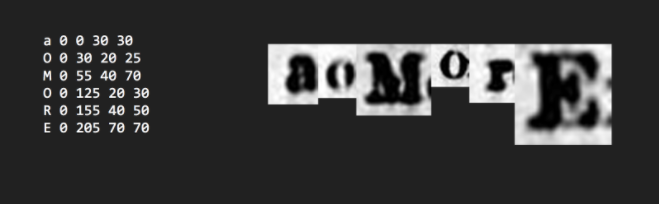
With these coordinates, we can construct the image and text files needed to train Tesseract to better understand the documents it is scanning. Problem is, we can’t train a neural network with this information directly, since the value of each character is set to whatever Tesseract thought it was during its initial OCR pass. No new information has been added, so the neural network would not be able to improve.
Introducing “The Educator”
The Educator is a small web app which takes the character data produced by Tesseract and asks a person whether or not a specific letter it is displaying is the letter it thinks it is. If no, they either correct it or tell us that what had been scanned was not, in fact, a letter.

We can now teach Tesseract how to read the different views of each alphanumeric character appearing in the newspaper, and we can create different sets of views for the different decades that we want to scan.
But, this is still a largely manual process. A person has to sit down and tell the computer what letter is what, and that can become tiresome after a while – even with tools such as the Educator that make the job a bit easier. Manually correcting 1300 characters via the Educator takes approximately an hour and that is a drop in the ocean compared to the many millions of examples found by Tesseract.
Scaling up the Educator
We are considering several options to to tackle this problem, the FT’s equivalent of Google’s use of reCaptcha to parse street signs and house numbers on Google Maps, and analysing astronomical data for signs of E.T. with SETI@Home.
In no particular order:
- Wait for OCR technology to improve. This seems like an increasingly viable approach, given the recent strides in Machine Learning.
- Simply publish extracts from the archive and invite readers to respond if they spot typos
- Offer a prize for readers finding the ‘best’ transcription errors (see the ‘slightly fairer’ example image in the previous post for just such an error …)
- Offer short-term subscriptions to readers in return for transcribing articles
- Offer a Quid Pro Quo to readers running Ad Blockers – transcribe a few blurry words and we’ll stop nagging.
- … and many more
This and the previous (archive-related) post are based on notes from a presentation given at Barcamp Southampton.