We've become increasingly submerged by information emanating from various feeds: social media timelines, push notifications, alerts, etc., all demanding our attention. It is proving difficult to scan the content of all those streams of information. Twitter Digest is an experiment that attempts to surface content from a stream in meaningful groupings, allowing users to explore each content group at a different pace and time, or skip it altogether.
Twitter Digest, explained
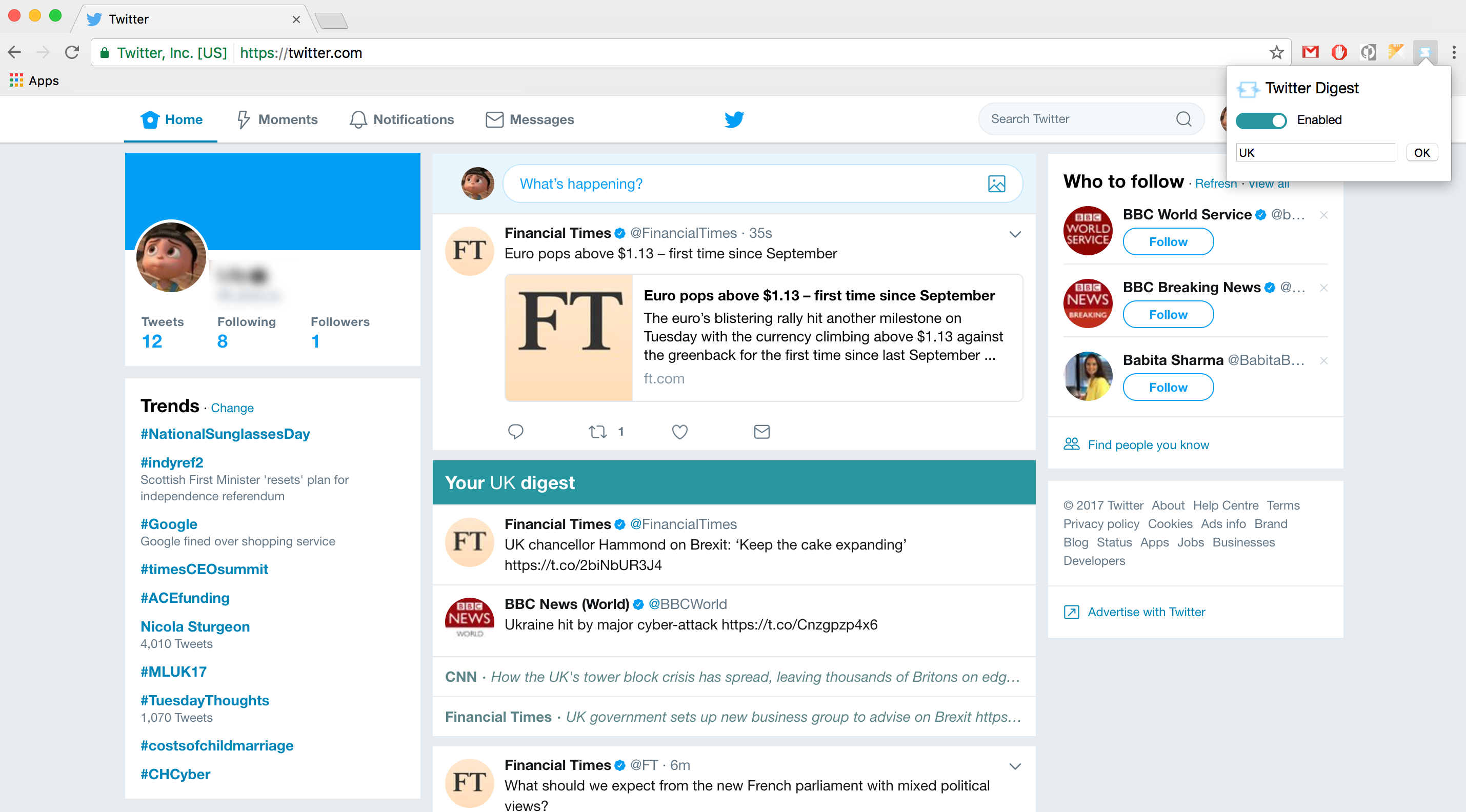
We focused our experiment on one of the most popular streams of information, Twitter. By combining Twitter and a Chrome extension, users were able to group content around a word of their chosing.
Any tweet in the user's timeline containing the keyword is then 'extracted' from it and appears in a cluster at the top of the timeline. It is then up to them to choose to explore the tweets in the cluster or scroll past them.
Twitter Digest is merely an attempt to reduce the scattered noise in a feed by condensing and surfacing tweets. It differs from other filters or "spoiler alert" type of extensions as it doesn't hide or dismiss any content but offers a more nuanced reading mode. This comes as a benefit to the user who get both a condensed view of selected tweets and a less noisy list of all the other ones.
Technical details & challenges
Twitter Digest comprises of a Node server, which handles authentication and keyword requests, and a Chrome extension which interacts with the client side (in this case the DOM of twitter.com).
The app isn't in the Chrome app store, but instructions on how to install it are with the source code is available on GitHub.
In the early stages of the prototype, Twitter Digest didn't allow for a choice of keyword and required a JSON object to be pasted in the popup of the extension to be processed. It can now handle switching between accounts, signing in with Twitter and toggling the digest on and off. We have made a few discoveries throughout the process.
Twitter API
It took a few tries to find the correct endpoint of the Twitter API for the digest. After considering user_timeline, we settled on home_timeline which offers the most accurate depiction of what is in a user's feed, although it excludes tweets the people you follow have liked and the 'In case you missed it section'.
OAuth, as always, has proved tricky, especially with the added layer of communication between the extension and the Node server. One thing to look out for when you set up your own Twitter application is to ensure you have all the necessary callbacks in place, and above all that the callback URL set when creating the application matches the one you've implemented. (This needs to be amended when switching from a local environment to a live server).
Chrome extension
If you're new to Chrome extensions, there are several things to know: the manifest file is crucial for a Chrome extension to work. You should reference all the properties and domains that are going to be required in there (especially to avoid CORS issues).
Chrome extensions are divided in 2 to 3 (JavaScript) parts; the background which is the nervous system of the app and distribute actions accordingly to the other parts. Then there's the popup, which is the content revealed when a user clicks on the icon; in our case it presents a toggle to enable/disabled the digest and a field to choose a keyword. And a third file that gets injected in the DOM of pages where the extension is allowed and active.
Beyond Twitter
At a time where Fear OF Missing Out is almost palpable, condensed feeds of information start appearing in various places. Email clients, such as Google Inbox or Outlook's Focused Inbox feature, seem to be particularly fond of this mode of display. However, the information displayed is algorithmically determined. The ability to curate your own feed of information is the differentiating factor of Twitter Digest. This new reading mode can also be applied to other streams of information, such as FT's News Feed.
Enhancements & issues
At the moment, the application is only filtering content from a tweet's text content, it doesn't explore the content of Twitter cards, or images' 'alt' attributes.
The way the tweets are organised in the digest depends on their "popularity" score, which is a combination of the amount of likes and retweets for each tweets. We could envisage different user-determined ways to weigh the digest (e.g. prioritise tweets from a specific user over another).
The Twitter API only gives a limited amount of the content displayed on a user's timeline. It excludes new features such as 'In case you missed it' and 'This user liked this', which makes the digest seem incomplete. There would be no workaround other than scraping the page at this point.
There is no selection mechanism in place other than string comparison at the moment. An improvement would be to use semantic processing for a more accurate digest (e.g. a search for 'Trump' would also include 'the White House' or 'the President').