Every year, the FT hosts an internal hackathon to spark new product ideas. JanetBot’s inception was at the 2017 event, trying to address the ‘Engaging women’ category. It is rare that a hackathon idea finds its way straight into production, but a couple of them did that year. JanetBot is the result of a collaboration between FT Labs, Data Analytics, Editorial Technology, and the FT newsroom (via the Audience Engagement team).
This tool is based on the premise that there are too many “suits” (read “men in suits”) on the FT homepage, according to our customers’ feedback. This is not representative of our readership. Our hypothesis is that female readers might engage more if there are visible reflections of themselves on the page.
The lack of female role models in the media is not an isolated issue, as this study of women in films by Google and the Geena Davis Institute on Gender in Media shows. To tackle the problem at our level, we created a tool to run an analysis of gender ratios in the images on the FT homepage.
Introducing JanetBot
JanetBot uses Computer Vision to determine which images can be classified as “man”, “woman” or “undefined”. It gives a general classification for the image, rather than individual people represented. So if there is at least one woman in the image, it will get classified as “woman”. “Undefined” is reserved for images where there are no people, or faces are too small or not identifiable.
Images (both main article images and columnists’ headshots) are analysed on our server every 10 minutes and are then distributed in two ways:
- Results are sent out to a Slack channel in Editorial at scheduled times throughout the day; these times have been picked to match moments when the homepage curation is likely to change, and are in place to minimise disruption.
- At any time, the results are visible on the homepage via an internal plugin. Images are colour-coded with a palette that plays to gender stereotypes to be identified “at a glance”.

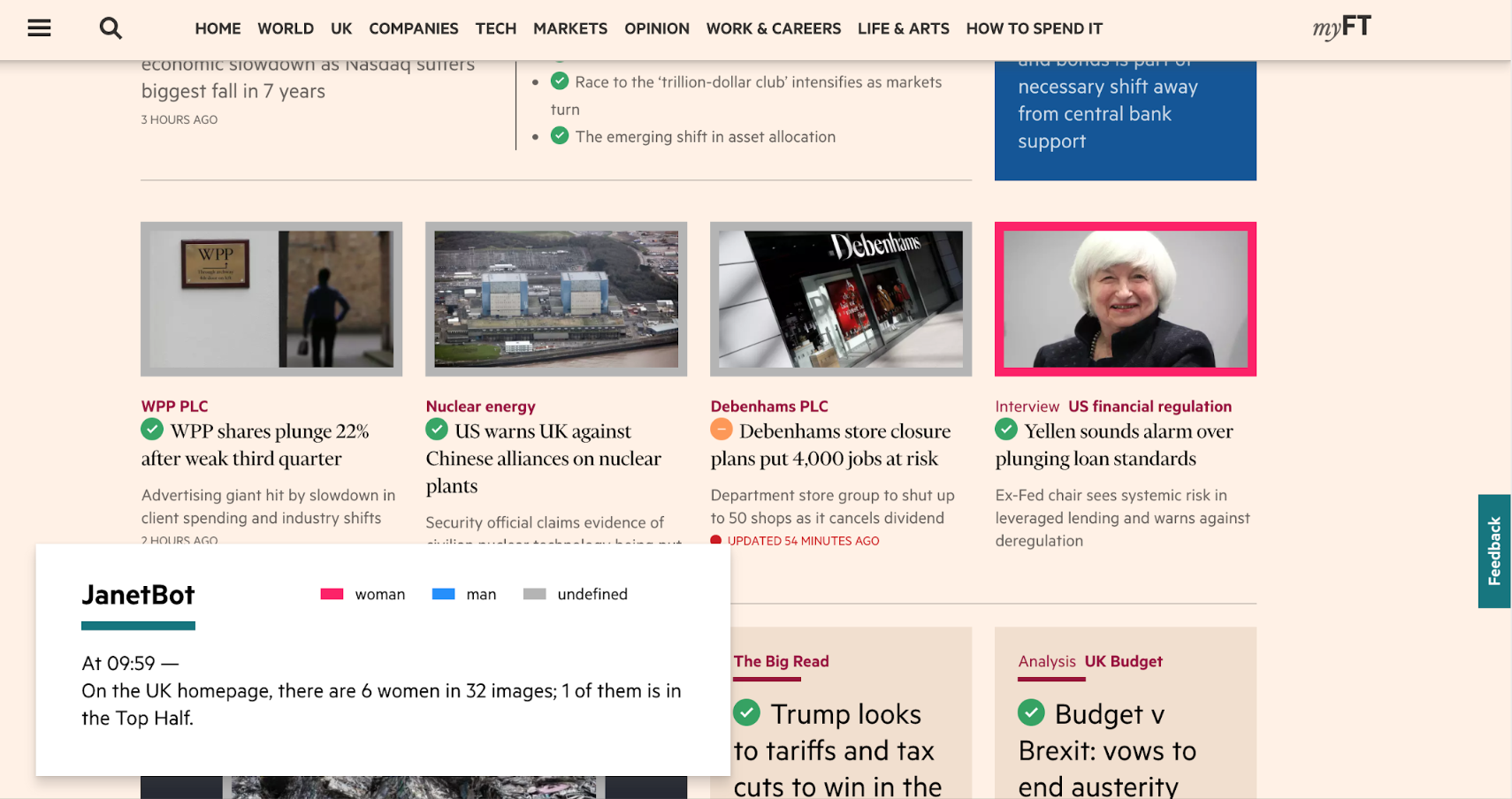
The results give the number of images classified as “man”, and the number of images classified as “woman”, out of all the images on the page. There is an emphasis on the first few articles ( what Editorial call the “Top Half”), as JanetBot aims to promote women’s visibility on the page.
The name of the tool itself is an homage to Ms. Yellen, who was featured in no fewer than three articles on the day the bot was first prototyped.
The primary focus since the reporting tool was launched in the newsroom has been to gather long-term data on the curation of our homepage, which will hopefully inform future selection.
The buzzwords section
The backend (a Node server) collects images from our content API, which are then classified using Machine Learning and Computer Vision. The original algorithm we used would try to assign a binary gender to any image, regardless of whether it featured people, leading to cars, buildings and logos being 52.345% male or female. When the project moved beyond hackathon stage, we had to implement a way to make the distinction.

We started our project before Amazon announced their Rekognition service. Yes, other providers were quite good, but were still giving some errors on a small sample. What’s more, we had hopes to train the model on our own corpus of images, making it more “FT”. We soon found that the OpenSource dataset we were running with could not compete with that of Amazon. More on that in a later post.
Amazon Rekognition tags faces with over 95% confidence in most cases, which allows us to note anything below that rate, and discard the results at a later date. Even with a high confidence, the algorithm does not distinguish the main subject of an image from background characters. There could be a woman walking in the background, while President Macron is in focus, and the image would be (rightly, from the algorithm’s point of view) classified as “woman”; whereas JanetBot’s aim is to highlight visible female role models on the page.
Similarly, in the picture below, the result would be “woman” because of the girl identified in the top right corner.

In this other example, the image would be classified as “man” because of the figure on the banknotes.

It is to avoid these kinds of mistakes that JanetBot also comes with a correction mechanism, where human operators can rectify a classification.
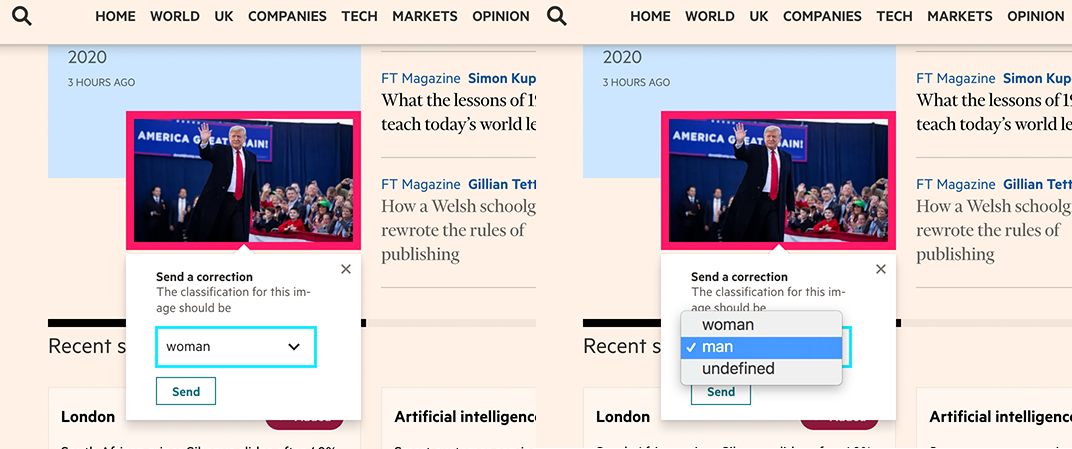
“What makes a woman?” is a tricky question that has been repeated time and again throughout development. “How do you handle crowds?”: it’s a call for Editorial and the picture desk. The lesson here is that AI is trendy and wonderful, but not everything can be inferred from an image (non-binary genders, for example). Algorithms lack context and human sensitivities and nuances, and that’s not to be forgotten.
JanetBot, under the hood
The service is tailored to the ft.com homepage which follows a complex set of article streams, rules, and layouts. For example, almost all articles have a main image, which is only displayed according to the layout and its position on the homepage. Whether or not an image is displayed does not come from our content API and has to be worked out by filtering the list of articles present on the page. This part is handled by a Node server which also sends the images to Rekognition and caches the results locally
Those results are then polled by the front page to display the coloured borders, and hooked into Slack (in different teams and channels). There is also a dev channel setup for debugging purposes, that reports errors with various APIs and actions.
Many edge cases became apparent throughout development. Opinion is not always opinion. There are particular cases when columnists’ headshots are displayed. Opinion pieces also occasionally find their way into the Top Half where a headshot could be shown. Videos and pieces hosted on subdomains had to be catered for.
Another one of our challenges was to handle the various editions of the homepage, which vary depending on a reader’s region, and how to transmit the results to users looking at the page in a different region.
Towards a diverse future
After a few months of Machine Learning setbacks, and uncovering/handling edge cases, JanetBot launched in the newsroom to a select group of users. For now, we are saving numbers, analysing, and hopefully informing Editorial’s decisions on article and image curation.
We hope these tools will help the FT offer greater variety in its images, and the stories commissioned. But we are aware it will prove challenging.
Future features might involve a study of diversity beyond gender, although as we’ve seen, when machines are involved, this is a delicate subject. Another possibility would be to have automated suggestions of articles for the front page, particularly if contextual data such as the author, or people mentioned in an article.
Focusing on visual diversity (images) was the most straightforward solution in a hackathon setting and as a first product iteration; but it is only a starting point.